
OpenAI o1 self-play RL 技术路线推演AI界的“内卷”大戏,谁才是最终赢家?

最近,OpenAI o1 self-play RL 技术路线推演成了AI圈的热门话题,大家都在问:这波操作到底有多“卷”?🤔 从AlphaGo到ChatGPT,AI的进化速度简直比“双十一”的快递还快!这次OpenAI的self-play RL技术,不仅让AI自己跟自己“打架”,还玩出了新高度。想知道AI如何“内卷”出最强版本? 跟着我一起揭秘这场技术大戏,保证让你直呼“好家伙”!
目录导读
1. 什么是self-play RL?AI界的“左右互搏术”
self-play RL,简单来说就是AI自己跟自己玩,通过不断对战来提升能力。这就像金庸小说里的“左右互搏术”,自己打自己,越打越强。
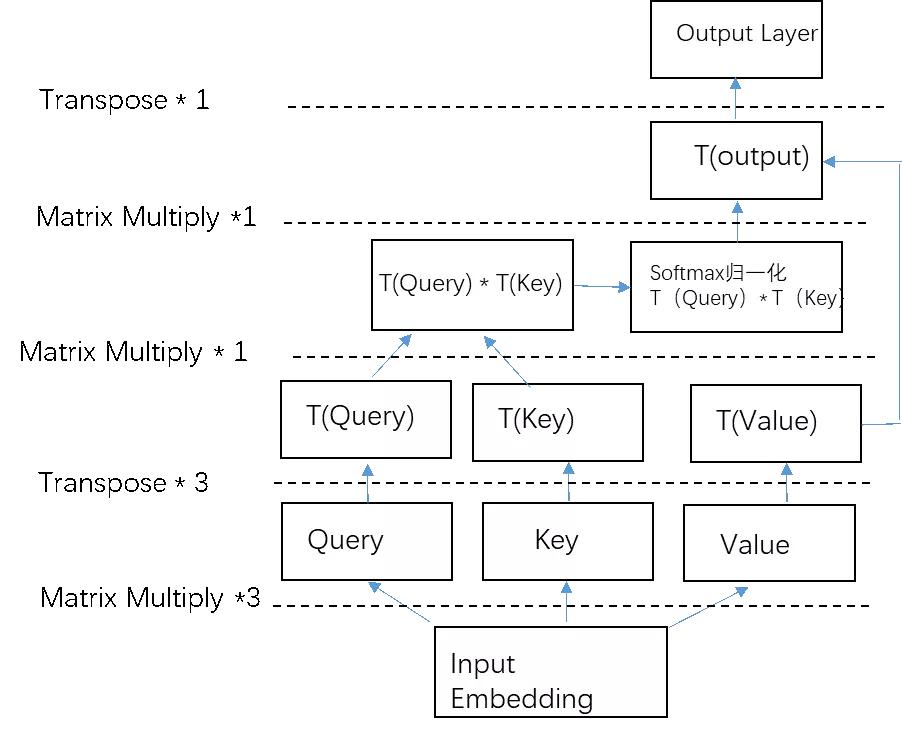
- AI的“内卷”之路:从AlphaGo到OpenAI Five,self-play已经成为AI训练的“标配”。
- OpenAI o1的突破:这次OpenAI o1不仅玩self-play,还加入了更复杂的策略推演,让AI的“内卷”更上一层楼。
2. OpenAI o1的技术路线:从“单机版”到“联机版”
OpenAI o1的技术路线,可以说是从“单机版”升级到了“联机版”。以前的self-play更像是一个AI在“单机模式”下训练,而o1则引入了多AI协作和对战,让训练更加高效。
- 多AI协作:多个AI同时训练,互相学习,效率翻倍。
- 策略推演:AI不仅对战,还会推演对手的策略,真正做到“知己知彼”。
3. self-play RL的应用场景:从游戏到现实
self-play RL的应用场景,已经从游戏扩展到了现实世界。比如在自动驾驶、金融交易等领域,self-play RL都能发挥巨大作用。
- 自动驾驶:AI通过self-play模拟各种驾驶场景,提升应对复杂路况的能力。
- 金融交易:AI通过self-play推演市场变化,做出更精准的投资决策。
4. OpenAI o1的挑战:AI的“内卷”极限在哪里?
OpenAI o1的挑战,主要在于如何突破AI的“内卷”极限。self-play虽然能提升AI的能力,但也存在“过拟合”的风险,即AI只擅长特定场景,无法应对新问题。
- 过拟合问题:AI在self-play中可能只学会特定策略,无法泛化到新场景。
- 计算资源:self-play需要大量计算资源,如何优化训练效率是关键。
5. 未来展望:self-play RL将如何改变AI行业?
self-play RL的未来,充满了无限可能。随着技术的不断进步,self-play RL将在更多领域发挥重要作用,甚至可能改变整个AI行业的格局。
- AI教育:self-play RL可以用于AI教育,帮助新手AI快速成长。
- 人机协作:self-play RL将推动人机协作的发展,让AI更好地服务于人类。
6. 常见问题:关于self-play RL,你想知道的都在这里
<FAQ>
<question>self-play RL是什么?</question>
<answer>self-play RL是一种AI训练方法,通过AI自己跟自己对战来提升能力。</answer>
<question>OpenAI o1有什么突破?</question>
<answer>OpenAI o1引入了多AI协作和策略推演,让self-play更加高效。</answer>
<question>self-play RL有哪些应用场景?</question>
<answer>self-play RL可以应用于自动驾驶、金融交易等多个领域。</answer>
<question>self-play RL的挑战是什么?</question>
<answer>self-play RL的挑战包括过拟合问题和计算资源需求。</answer>
</FAQ>结语
OpenAI o1 self-play RL 技术路线推演,不仅是AI技术的又一次突破,更是AI“内卷”的极致体现。未来,AI将如何继续“卷”出新高度? 让我们拭目以待!🚀










 京公网安备110000000001号
京公网安备110000000001号 京ICP备110000001号
京ICP备110000001号